Searching for inscriptions¶
This section is a guide for using the search capabilities of Rundata-net. These have been briefly introduced in the section Query builder.
Query builder¶
A search query is created using the query builder. The query builder enables users to define search parameters and their groups. Occasionally, the term ‘filtering’ is used interchangeably with ‘searching’ in this application.
Each rule consists of a property, an operation, and a search value. The property is what
you are searching for, the operation is the action to be performed, and the search value is
the criterion to be met, which may include multiple values. For example, consider the query
Signature begins with Öl. In this case, Signature is the property being searched,
begins with is the operation, and Öl is the value. The result of this search is
a list of inscriptions with a signature that begins with ‘Öl’.
The list of available search properties is based on Meta information
and Inscription texts. The property ------ is a placeholder.
Let’s consider an example of the query builder interface in action.
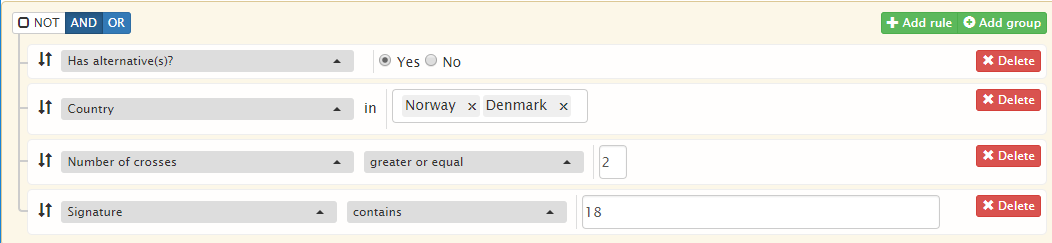
First, note the top left corner. It contains the buttons NOT, AND, and OR. These buttons represent logical operations that can be applied to search parameters and search groups:
NOT inverts the search of a parameter/group. For example, if a parameter/group search results in find all inscriptions in Denmark, the inverse search will be find all inscriptions NOT in Denmark.
AND performs a logical AND operation between parameter/group search values. It can be used to group independent properties. For example, find all inscriptions from Denmark AND find inscriptions that have at least one cross will return all inscriptions from Denmark with at least one cross.
OR performs a logical OR operation between parameter/group search values. It can be used to return results that match any of the search values. For example, find all inscriptions from Denmark OR Norway will return all inscriptions from Denmark and Norway. Another example is find all inscriptions from Denmark OR inscriptions that have at least one cross will return all inscriptions from Denmark and all inscriptions that have at least one cross.
For more information on NOT/AND/OR, you can refer to this Wikipedia article on logical disjunction .
The currently selected operator is indicated by a slightly darker blue colour. In the figure above, AND is selected. NOT is a checkbox and has a tick when selected.
One way to determine which logical operation is applied to each search parameter is to follow the grey line from the logical operators to the search parameters.
The control buttons are located to the right. They are used for adding or deleting search parameters and groups, see the figure above.
Search parameters¶
Remember the figure
that contains four search parameters. Each search parameter has its own operator and value type. Let’s look at the existing value types through the example query:
Boolean type (search parameter Has alternative(s)?). This type typically has a Yes/No value.
Categorical type (search parameter Country). This type contains one or several items from a predefined list.
Numerical type (search parameter Number of crosses). This type contains an integer or decimal number.
Textual type (search parameter Signature). This is the most common type and contains textual information, which may include letters, special symbols, or digits.
An operator is an action that is performed on the search value:

In a search parameter Signature begins with N, the operator is begins with and the search value is N. The search returns all inscriptions with a signature that begins with N.
Different search types have different operators. Their meanings should be clear from their names.
Attention
Both Rundata-net and Rundata support two types of searches:
Direct search by value. In this case, the user selects a property to be searched for some value. For example, a search for inscriptions from Sweden. This search uses the value ‘Sweden’ to search in the property ‘location’.
Word search, or a search across different text forms. In this case, the user provides multiple search patterns in different inscription texts. All patterns must be present in a single word. Such a search is illustrated in the example below.
Case sensitivity in searches and search normalization¶
Rundata-net supports case sensitive and case insensitive searches for text search types. Each text-based rule has a Match case / Ignore case toggle on the right-hand side of the rule. A single search query may therefore mix case sensitive and case insensitive rules.
To illustrate case sensitive searches, consider a search for inscriptions via Translation to English:
Translation to English contains Who (case sensitive). This search returns inscriptions with translations that contain the letters Who. Currently, such a query returns 11 inscriptions.
Translation to English contains Who (case insensitive). This search returns 236 inscriptions.
The same Match case / Ignore case toggle is also available for the rules that deal with Inscription texts, namely:
Transliteration and Normalization “Old Scandinavian”;
Transliteration and Normalization “Old West Norse”.
By default these rules are case sensitive, so a search for R in transliterated runic text only yields results that contain a literal R. Toggle Ignore case on the rule to match r as well.
Rundata normalizes all inscription texts, so that a search for Ol matches Öl. Rundata-net does not perform such normalization.
Another type of normalization concerns punctuation and special editorial symbols in normalized
texts. By default, Rundata-net removes editorial symbols (" < > | [ ]
( ) { } ^ ´ ?) from both the inscription data and the query before
comparing. This means that a search for skarf in transliterated text yields s:karf as
one of its results, and a search for Þórr also matches the personal-name annotation
"Þórr".
Each normalization/transliteration rule has an Ignore symbols / Include symbols
toggle. Switch it to Include symbols if you need the editorial markers to be part of
the comparison (e.g. to explicitly look for personal-name markers or for the | word-binding
character). Refer to Data in the database for the full list of editorial characters.
The character - is not stripped. If you want to find f-ita you have to search for
f-ita.
Search example¶
Find all inscriptions from Norway that are dated with U. There are several
ways of running such a search. One possibility is to define two rules connected with
AND:
Country in Norway.
Dating begins with U.

Find all inscriptions from Norway that are dated with ‘U’.¶
This search finds 129 inscriptions. Use of the begins with operator leads
to the inclusion of such dating values as U ca 450-550, U 520/530-560/570 (Imer 2007),
and so on. If one wishes to search only for U, then begins with
should be replaced with equal. A search using equal yields 67 inscriptions.
Now imagine that we wish to add a search for inscriptions from Denmark, dated M. One way to do this is to add a new group. Click
Add group and a new group with an empty rule appears under the
existing rules. We may add two rules to this group:
Country in Denmark.
Dating equal M.
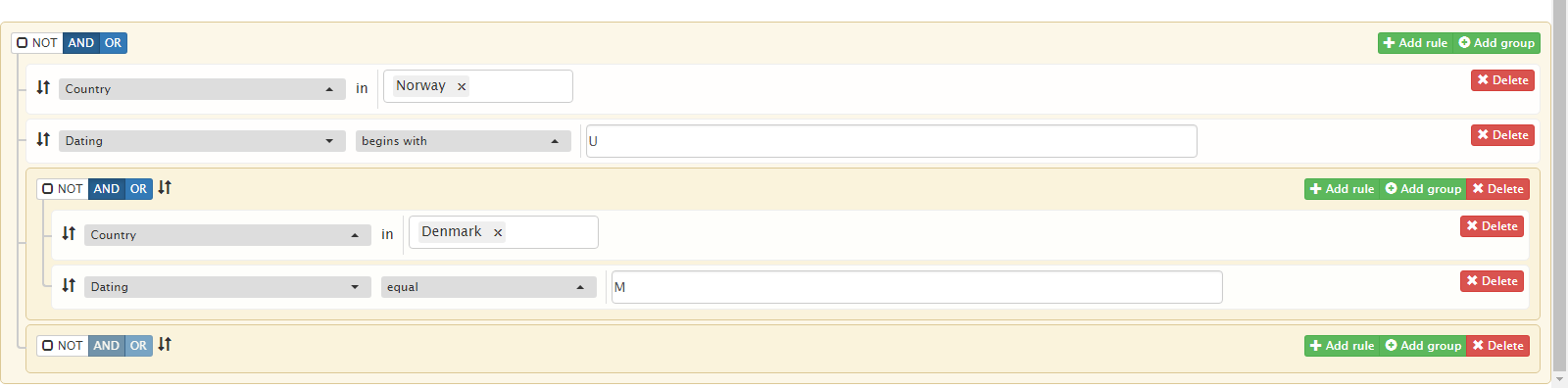
Filtering with a group¶
Such a search returns no results. This is due to the way groups are combined (processed) by logical operators.
If we now change the logical operation of the very top row from AND to OR, the search yields 2108 inscriptions. The difference is that with AND we are searching for inscriptions that are from Norway AND from Denmark AND have dating equal to U AND M. Obviously, there are no such inscriptions. With OR, on the other hand, we are searching for inscriptions that are from Norway OR have dating U OR are from Denmark with a dating equal to M.
You may have spotted a small glitch in this version as well. We get extra inscriptions because we have searched for inscriptions that are from Norway OR have the dating U, instead of searching for inscriptions from Norway dated U. This can be corrected:
Create a new top group.
Move two first filters into that group. You can easily rearrange rules and groups with the mouse by dragging them to the sort icon ↓↑.
Delete the placeholder rule for the group.
The final arrangement of rules is shown in the figure below. Note that the first logical operation is OR, whereas the others have the value AND.
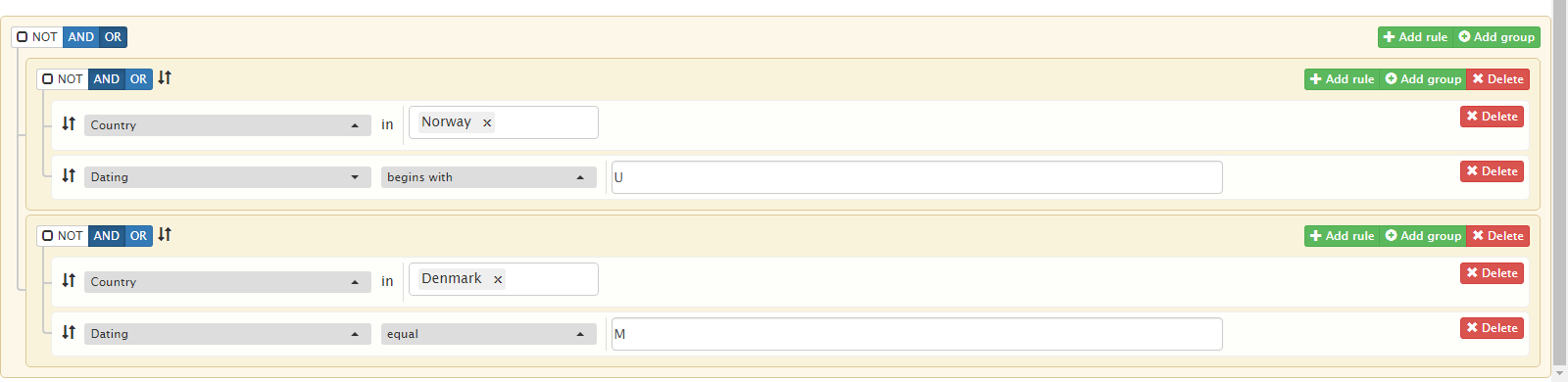
We now get a mere 310 inscriptions.
Search across different text forms in inscription texts¶
A second search type supported by Rundata-net is a search across different text forms in inscription texts. This search type is sometimes referred to as word search. It is called word search because it yields results where the inscription contains the search pattern in a single word. Refer to the structure of inscription texts: each word is given in multiple forms, i.e. transliterated and normalized. Search patterns are evaluated per word in a word search. This can be useful if one wants to find how word spelling changed over time.
One example is to find out when rune a is normalized (Old West Norse) as ei.
Runic word stain can be normalized as stein or staina. In order to find
all inscriptions that have word stain normalized as stein, a word search must be
used. A similar example is that normalization stein can be transliterated as stin
or stan.
In Rundata-net, word search is available through two dedicated rules under the Texts group:
Transliteration and Normalization “Old Scandinavian”;
Transliteration and Normalization “Old West Norse”.
Each of these rules takes two input fields — one for the normalization pattern and one for the transliteration pattern — plus a radio button group for handling personal names (Include personal names, Exclude personal names, Personal names only). The supported operators are contains, equal, begins with, and ends with. You can fill in either one or both input fields:
If only one is filled in, the matching runs against that single text form.
If both are filled in, the search looks for words at the same position where both patterns match.
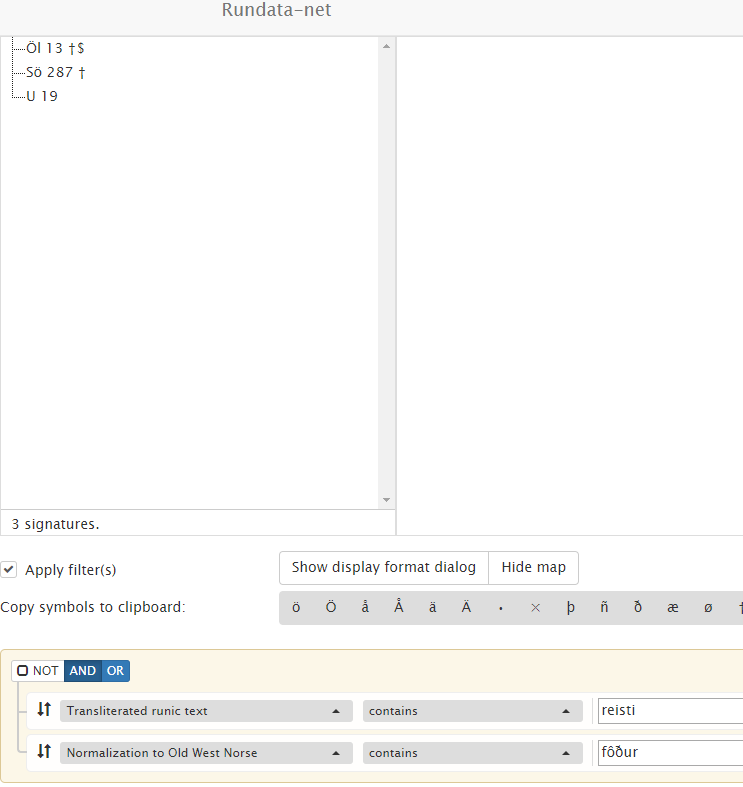
For example, specifying reisti for transliteration and fôður for Old West Norse
normalization returns no results, because there is no single word that is reisti in
transliteration and fôður in its normalization. In contrast, separating the two patterns
into two unrelated rules (one rule per text form) would perform two independent whole-text
searches and would return inscriptions where both strings appear anywhere, regardless of word
position.
Consider now a search for all inscriptions from Gästrikland with a in transliteration and
ei in the Old West Norse normalization aligned on the same word. Rundata-net finds eight
inscriptions. The first one, Gs 1, has its matched words highlighted:
The logic is:
Word 3 is
reisain Old West Norse — it containsei. Word 3 isresain transliteration — it containsa. Therefore, word 3 is a match.Word 4 is
steinin Old West Norse — it containsei. Word 4 isstainin transliteration — it containsa. Therefore, word 4 is a match.
The corresponding rules in Rundata-net are:
Country in Gästrikland.
Transliteration and Normalization “Old West Norse”, operator contains, Normalization =
ei, Transliteration =a.
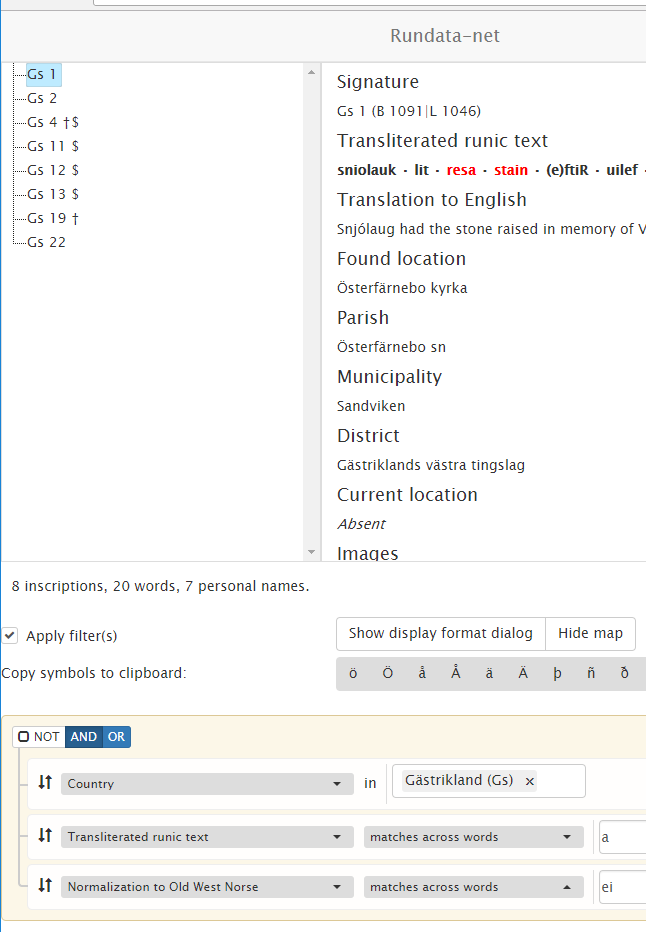
Note that when a word search is performed, additional information about the number of matched words and personal names is displayed together with the number of inscriptions. For this search there are 20 words, of which 7 are personal names — i.e. 13 words other than personal names. The matched words are highlighted when the inscription is selected for display.
If you select all the inscriptions and glance through their texts, you might notice that more than 20 words are highlighted. The word counting function does not take into account words repeated in alternative readings. This means that if a runic inscription text is:
§P þiuþkiR uk| |kuþlaifr : uk| |karl þaR bruþr aliR : litu rita stain þino × abtiR þiuþmunt ' faur sin ' kuþ hialbi hons| |salu| |uk| |kuþs muþiR in osmuntr ' kara sun ' markaþi × runoR ritaR þa sat aimunt
§Q þiuþkiR uk| |kuþlaifr : uk| |karl þaR bruþr aliR : litu rita stain þino × þa sata| |aimuntr| |runoR ritaR abtiR þiuþmunt ' faur sin ' kuþ hialbi hons| |salu| |uk| |kuþs muþiR in osmuntr ' kara sun ' markaþi ×
and your search results contain the word þaR, this word is counted only once despite
being present in both the §P and the §Q variant.
Warning
Rundata counts words in a similar manner. However, if variant §P contains three words and variant §Q contains four words, Rundata will only report three words for that signature, whereas Rundata-net will report four words.
Extending word search in Rundata-net¶
Let us extend the previous search to find all inscriptions from Öland which contain þenna
in the normalization to Old Scandinavian:
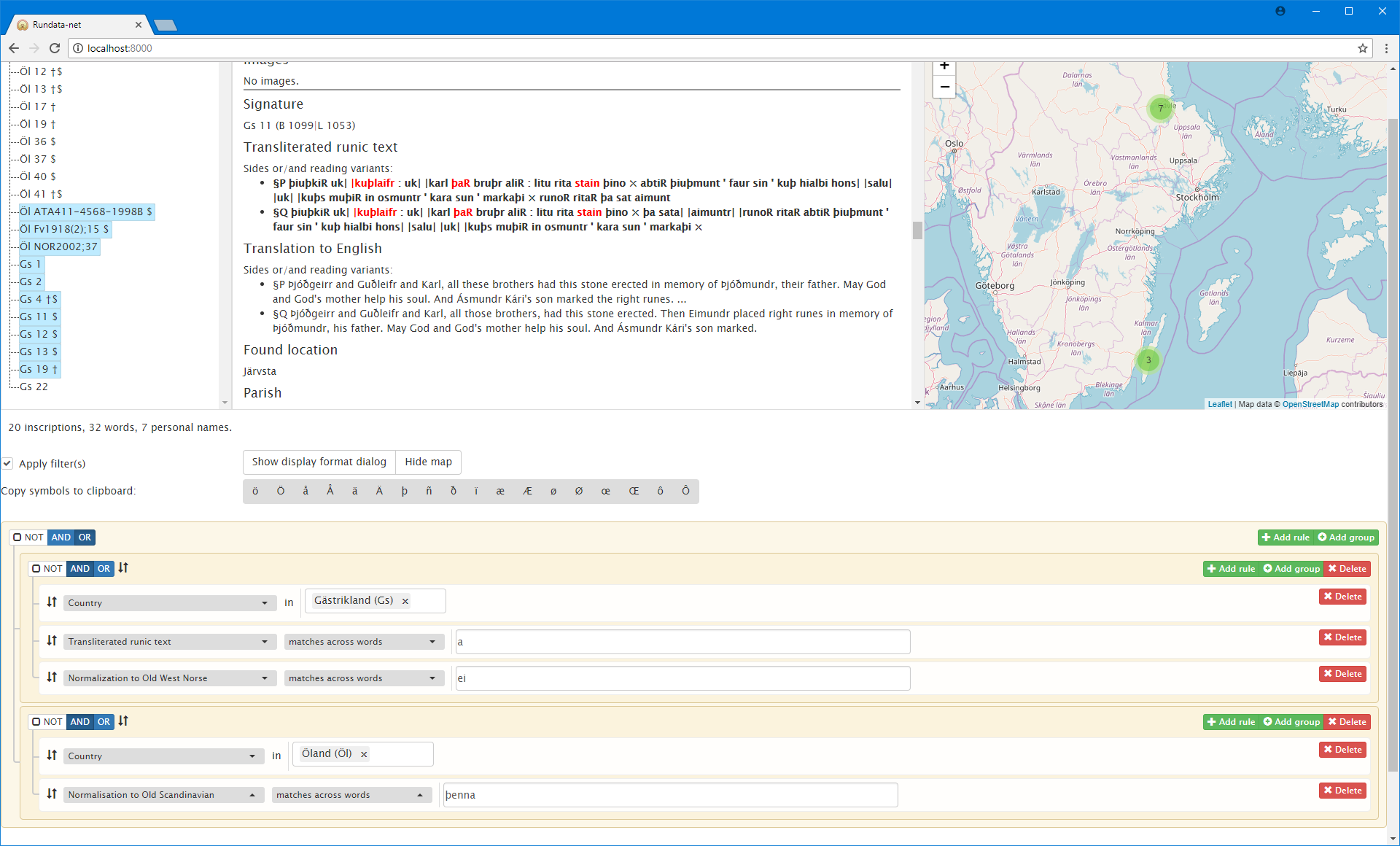
This search results in 20 inscriptions and 32 words, of which 7 are personal names. It adds 12 inscriptions and 12 words, but no personal names.
Phrase (multi-word) search¶
The word search described above evaluates the pattern against one word. Rundata-net also supports searching for a phrase — a sequence of consecutive words — simply by separating the words with whitespace in the same input. No extra UI toggle is needed: any query that contains a space is treated as a phrase.
Phrase search is available for both the transliteration input and the normalization input of the two word-search rules. The matched highlight covers the whole phrase contiguously.
Per-operator semantics (with N words in the phrase)¶
contains — every phrase word must appear as a substring of the corresponding consecutive inscription word. This behaves like single-word contains (
String.includes), applied to each position in parallel. Soes sattmatcheses sattrexactly the same way that single-wordsatmatchessattr.equal — every phrase word must match the corresponding consecutive inscription word exactly.
es sattrmatcheses sattr;es sattdoes not.begins with — the inner words must be exact; the last inscription word must start with the last phrase word. So
es sattmatcheses sattr;e sattrdoes not.ends with — the first inscription word must end with the first phrase word; the remaining words must be exact. So
sed stonematchesraised stone;raised stondoes not.
Phrase searches are not anchored to the start or end of the inscription: the matched window can appear anywhere in the text.
When both the normalization and the transliteration inputs are filled in, both phrases must start at the same word index in the inscription. The highlighted region is the union of both windows, so phrases of different lengths are both highlighted in full.
The rules for case sensitivity, editorial-symbol stripping, and the personal-names filter apply to phrase searches as well. The personal-names filter uses any-word semantics: with Exclude personal names, a window is rejected if any word in it is a personal name; with Personal names only, a window is accepted only if at least one of its words is a personal name.
Examples¶
Find
auk × nifRin the transliterated text — search forauk nifRwith contains. The×punctuation is stripped automatically.Inscription Öl SAS1989;43 contains
hir| |risti| |ik þiR birk ¶ bufiin the transliterated text. To find the first two words, search forir ristiwith contains. To find words 5 and 6, search forrk bu.Inscription Öl 1 contains
es sattrin the Old Scandinavian normalization. Searching fores sattwith contains finds Öl 1 and highlights both wordsesandsattrcontiguously. Searching fores sattwith equal does not match (the query must exactly equal the inscription words). Searching fores sattrwith equal does match.To search for
reisti steinas a phrase in the Old West Norse normalization, set the operator to contains, Normalization =reisti stein, and leave the Transliteration input empty. This yields every inscription where the two words appear consecutively in the normalized text.
Note
You can give phrase tokens only as they appear in sequence. Searching h ti against
hir risti will not match — the inscription has hir and risti as consecutive
words, and each phrase word must match its corresponding inscription word under the
chosen operator.
Notes about searching across words¶
Several things should be kept in mind when performing searches across words:
Each input is interpreted as plain text (literal characters, stripped of editorial symbols by default). Regular expressions are not supported.
Whitespace separates phrase tokens; runs of whitespace are treated as a single separator.
The logical NOT operator should not be used on word-search rules. Although the number of found inscriptions may be correct, the highlight mechanism will not work.
Searching for bind runes¶
You may recall from section Case sensitivity in searches and search normalization that the bind-rune symbol
^ is treated as a special editorial symbol. It is stripped from both the data and the
query before comparing, when the default Ignore symbols is active.
Let’s say you wish to find inscriptions that have f^u in the transliterated text.
With Ignore symbols active, the search Transliteration and Normalization
"Old West Norse" contains fu (Transliteration input) matches both fu and f^u.
It is thus impossible to automatically distinguish between cases where a bind rune was used
and cases where fu appeared without it. If you specifically want to search with
bind runes, toggle Include symbols on the rule and search for f^u directly.
The same is true when a bind rune connects two words. For example, inscription
Vg 76 contains the transliterated text h[-ær]ium : a^t^ ^biþia : bat[ær].
To search for it, you may use a phrase search: contains at biþia in the
Transliteration input.
Search capabilities not present in Rundata-net (compared with Rundata)¶
Rundata has some special symbols that may be used in word searches:
#Varbitrary vowel.#Karbitrary consonant.#Xarbitrary character.\used before a letter to indicate that it is to be searched for in this exact form (capital or lower case, with or without accent). Used before a special character,\means that the character is deprived of its special function and should be treated as an ordinary letter.@placed between two characters to indicate that there should be no punctuation mark between them.
These symbols are not supported in Rundata-net! Rundata-net also does not support regular-expression searches or full-text search across inscription meta data (Full text search in information file in Rundata).